blog · git · desktop · images · contact
2009-08-13
Man sagt Java ja nach, dass es lahm ist. So rein subjektiv gesehen kommt mir das auch ziemlich oft so vor, trotzdem sind es wohl meistens eher nur die GUIs und/oder "verschwenderische" Programmierer. Sagt man ja so.
Jetzt, wo das Multifrac so schön aufgeteilt ist, wollte ich's dann mal selbst rausfinden. Vorallem ist ein Mandelbrot-Loop ziemlich einfach und man hat es eigentlich nur mit primitiven Datentypen zu tun, folglich umginge man mit einem "Java vs. C"-Benchmark hier die subjektiven Gefühle und auch erweiterte Konstrukte relativ gut.
Also: Eine Rendernode in C gehackt, die -- aufgrund der Syntaxnähe von Java und C -- sich auch nur in Details vom Java-Code unterscheidet. Zumindest, was den rechenintensiven Mandelbrot-Loop angeht. Dazu kommt noch ein bisschen Netzwerk-Code, dessen zeitlicher Einfluss später auch noch separat gemessen wurde. Den absoluten Hauptteil der Zeit verbringt eine solche Rendernode aber damit, das Fraktal zu berechnen, was dann also auch Dreh- und Angelpunkt dieses Benchmarks ist.
Ich lasse also auf meinem Desktop-Rechner den Koordinator laufen und trage als Remote Host den zu benchenden Rechner ein. Diesen beschränke ich aus einem bestimmten Grund auf einen Kern: Wenn sich der Prozess auf mehrere Prozessoren aufteilt, wird es am Ende des Bildes zwangsläufig dazu kommen, dass nur noch ein Kern rechnet, da für den anderen nichts mehr übrig ist. Um insgesamt den Overhead durch Netzwerkverkehr gering zu halten, habe ich den Koordinator so gebaut, dass er jeden "Bunch" etwa 5 Sekunden rechnen lässt. Wenn nun Java und C unterschiedlich schnell sind, dann gibt es am Ende eine unterschiedlich starke Nebenläufigkeit, was das Ergebnis verschwimmen lässt. Je nach Setup würden, wie man sehen wird, 5 Sekunden auch schon etwas ausmachen. Daher immer nur ein Kern.
Gebencht wurde jeweils einmal ohne Supersampling und einmal mit 2x2 Supersampling. Aus mehreren Läufen wurde das beste Ergebnis genommen, wobei die Zeiten bei Java durchaus um 2-5 Sekunden schwankten, bei C aber ziemlich konstant waren.
Die C-Binary wurde einmal auf dem Desktop-Rechner mit dem GCC 4.4.1 und "-O2 -march=i686" kompiliert und dann verteilt.
Alter Testrechner:
Videorekorder:
Alter Arbeitsrechner:
Laptop:
Desktop:
Überall sind 100Mbit-NICs drin.
Testrechner:
kein AA 2x2 AA
-------------- ---------------
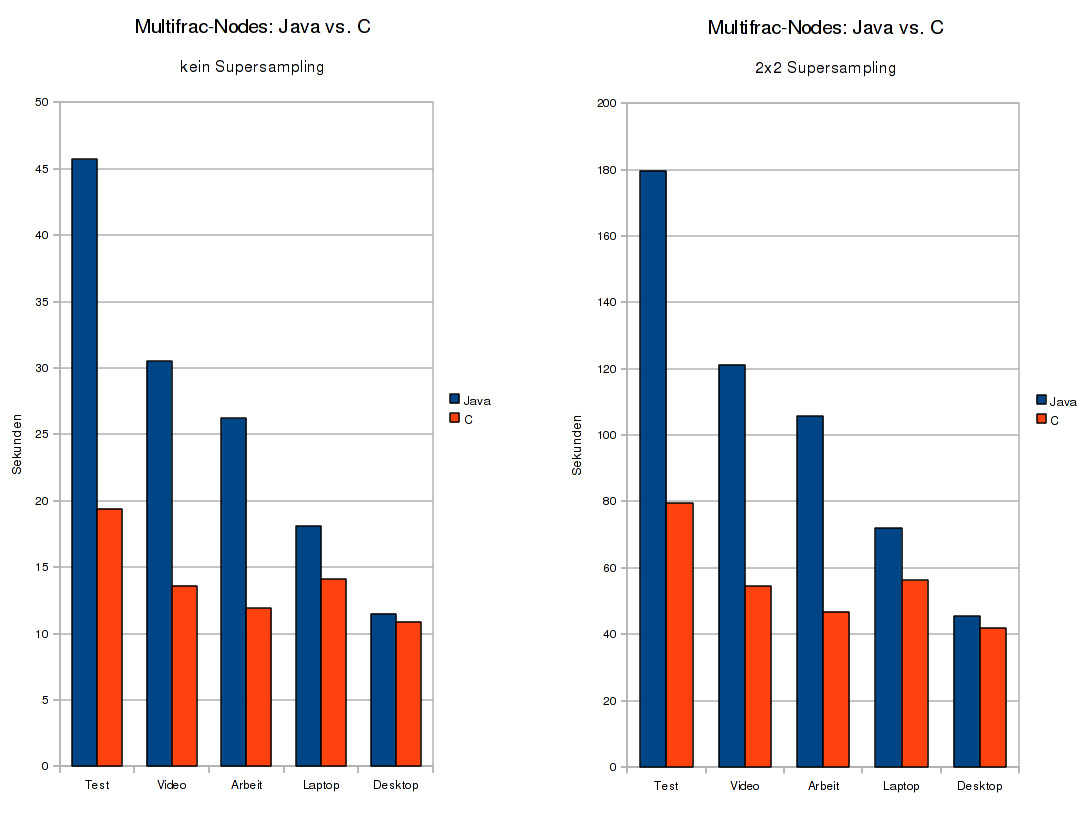
Java : 45.7s Java : 179.7s
C : 19.4s C : 79.5s
============== ===============
Speedup: 2.36x Speedup: 2.26x
Videorekorder:
kein AA 2x2 AA
-------------- ---------------
Java : 30.5s Java : 121.2s
C : 13.6s C : 54.5s
============== ===============
Speedup: 2.24x Speedup: 2.22x
Alter Arbeitsrechner:
kein AA 2x2 AA
-------------- ---------------
Java : 26.2s Java : 105.7s
C : 11.9s C : 46.8s
============== ===============
Speedup: 2.20x Speedup: 2.26x
Laptop:
kein AA 2x2 AA
-------------- --------------
Java : 18.1s Java : 72.0s
C : 14.1s C : 56.2s
============== ==============
Speedup: 1.28x Speedup: 1.28x
Desktop:
kein AA 2x2 AA
-------------- --------------
Java : 11.5s Java : 45.4s
C : 10.9s C : 41.9s
============== ==============
Speedup: 1.06x Speedup: 1.08x
Das ist ein sehr unerwartetes Bild. Man sieht einen deutlichen Sprung bei den "kleinen" Maschinen, die nur einen Kern besitzen -- die DualCores dagegen werden bei weitem nicht so viel schneller, der Laptop zwar noch 25%, aber der Desktop fast gar nicht. Ich hatte gedacht, dass Java höchstens 5-10% langsamer ist, da es sich eigentlich um sehr einfachen Code handelt, zum Beispiel ist bei den Nodes keinerlei explizites Locking involviert. Mit einem solchen Unterschied abhängig von der Hardware hatte ich nicht gerechnet.
Was könnte hier los sein:
Ich hoffe, dass damit alle offensichtlichen Fehlerquellen beseitigt sind. Eine mögliche Idee wäre, dass Java auf einem Mehrkernrechner mehr Zeit in die Optimierung zur Laufzeit steckt, Stichwort JIT. Allerdings muss ich mich da erst noch etwas schlauer machen, denn auf diesem Gebiet thront gefährliches Halbwissen. :D Sachdienliche Hinweise nehme ich da sehr gerne entgegen.
Trotzdem ein kurzer Blick auf den Desktop-Rechner mit beiden Kernen (Laptop als Koordinator). Hier habe ich mit 4x4 Supersampling rendern lassen, um den Effekt der ungleichen Nebenläufigkeit am Ende zu dämpfen. Wie man sieht, würden nämlich auch 2-3 Sekunden Unterschied schon ins Gewicht fallen:
4x4 AA
--------------
Java : 90.6s
C : 85.7s
==============
Speedup: 1.06x
So ganz zu obiger These passt das leider nicht, denn das entspricht dem Faktor von einem einzelnen Kern.
Tja, woran liegt das? Ich lasse das jetzt einfach mal so offen stehen. ;) Interessant finde ich die Beobachtung auf jeden Fall und es ist wirklich nicht das, womit ich gerechnet hatte. Wenn ich die Gelegenheit dazu habe, werde ich mal versuchen, tiefer in das Thema einzusteigen.
Den Code für die C-Node wird es dann demnächst auch im Multifrac-Repo geben, wenn er noch etwas aufgeräumter und getesteter ist. :)
{kind=link}