blog · git · desktop · images · contact
Advent of DOS
2023-12-25
Needless to say: This blog post contains spoilers.
Advent of Code is an Advent calendar where you get a new programming puzzle every day. 2021 was the first year I participated. AoC has a global leaderboard as well as private ones that you can join with a group of friends. All this nudges you into taking the event as a “competition”: Who’s going to solve the puzzles first?
In 2021, I kind of tried to “beat” others – and quickly realized how exhausting that is. It’s nice to win, but it requires a huge amount of energy and preparation. (And don’t even think about getting on the global leaderboard.) This isn’t my kind of thing. I don’t enjoy this, it’s stressful and I get grumpy. So, in 2022, I tried to avoid this issue by “making my own rules”: I wanted to learn more about Rust, so all solutions had to be written in that language. I wouldn’t look at the leaderboards and in fact left them.
For this year, my goal was something different:
Port as many solutions as possible to MS-DOS 6.22. They shall be written in C.
This doesn’t mean writing the code on DOS. That’s a bit too much. There were people who went that far – and beyond. Whoa.
– edit 2023-12-28: I just realized that this is precisely the person who I saw last year doing AoC on DOS. That’s the guy who inspired me to do it this year! :-)
Instead, I wrote the solutions on my normal Linux box and then compiled
them in a DOS VM on the same box. Once it works, I can take the .EXE
file and run it on my “museum PC”, that Pentium 133 with 64 MB of RAM
which has been mentioned in this blog a couple of times. Although, to be
fair, that is a bit of cheating: This machine came with Windows 95 and
it’s already way faster than actual DOS machines. When I got this
machine, I installed DOS on a second partition and then Windows 3.1,
which ran unbelievably fast at the time. But since I have no older
hardware, it’s what I’m going to use. (I sure do regret that we gave
away our IBM PS/2 Model 30 some 20 years ago. It probably
ended up in the bin.)

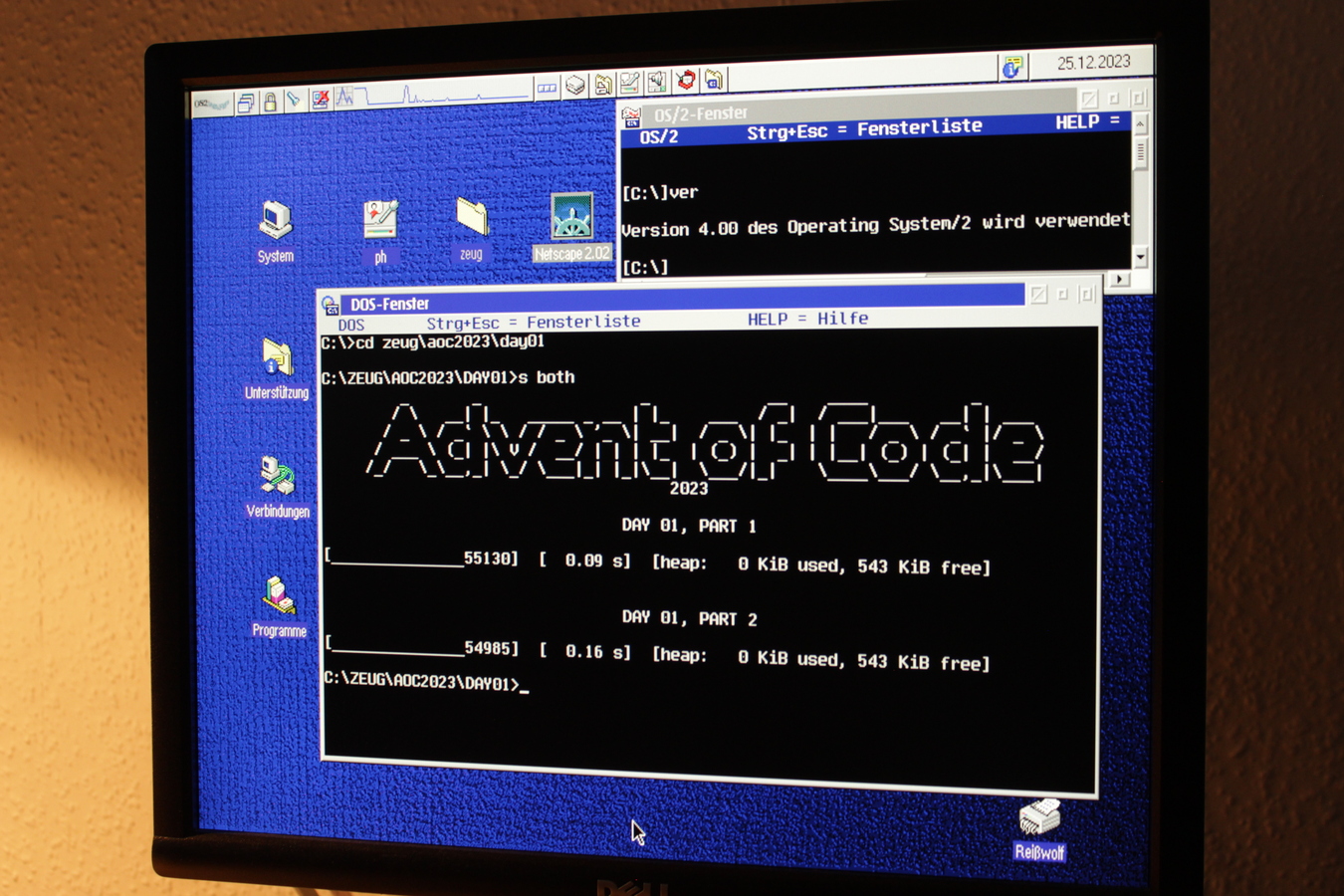
My build VM runs MS-DOS 6.22. For other weird reasons of nostalgia, I like running the programs on OS/2 Warp 4, that’s why you’ll see it on the photos and videos. And it’s easier to copy the files that way. The box has an ethernet NIC and networking is available on Windows 3.11 and OS/2, but the process is just a little bit smoother on OS/2. (I’m aware of tools like EtherDFS. I didn’t set that up, yet.)
This additional difficulty is balanced by allowing myself to look for help without feeling guilty. Writing the solutions in C and then getting them to run on DOS is probably hard enough. This event is supposed to be fun and not a guaranteed burnout. :-)
Soundtrack for this year’s AoC was definitely CoLD SToRAGE’s wipE'out" OST. Rest assured, I still have my CD from 1995.
You can have a look at my code from this year, but it’s probably not very interesting – see also the toplevel README on why it’s a bit “empty”. It does contain some notes, though, some of them DOS-specific:
git clone https://uninformativ.de/git/advent-of-code.git
cd advent-of-code/2023
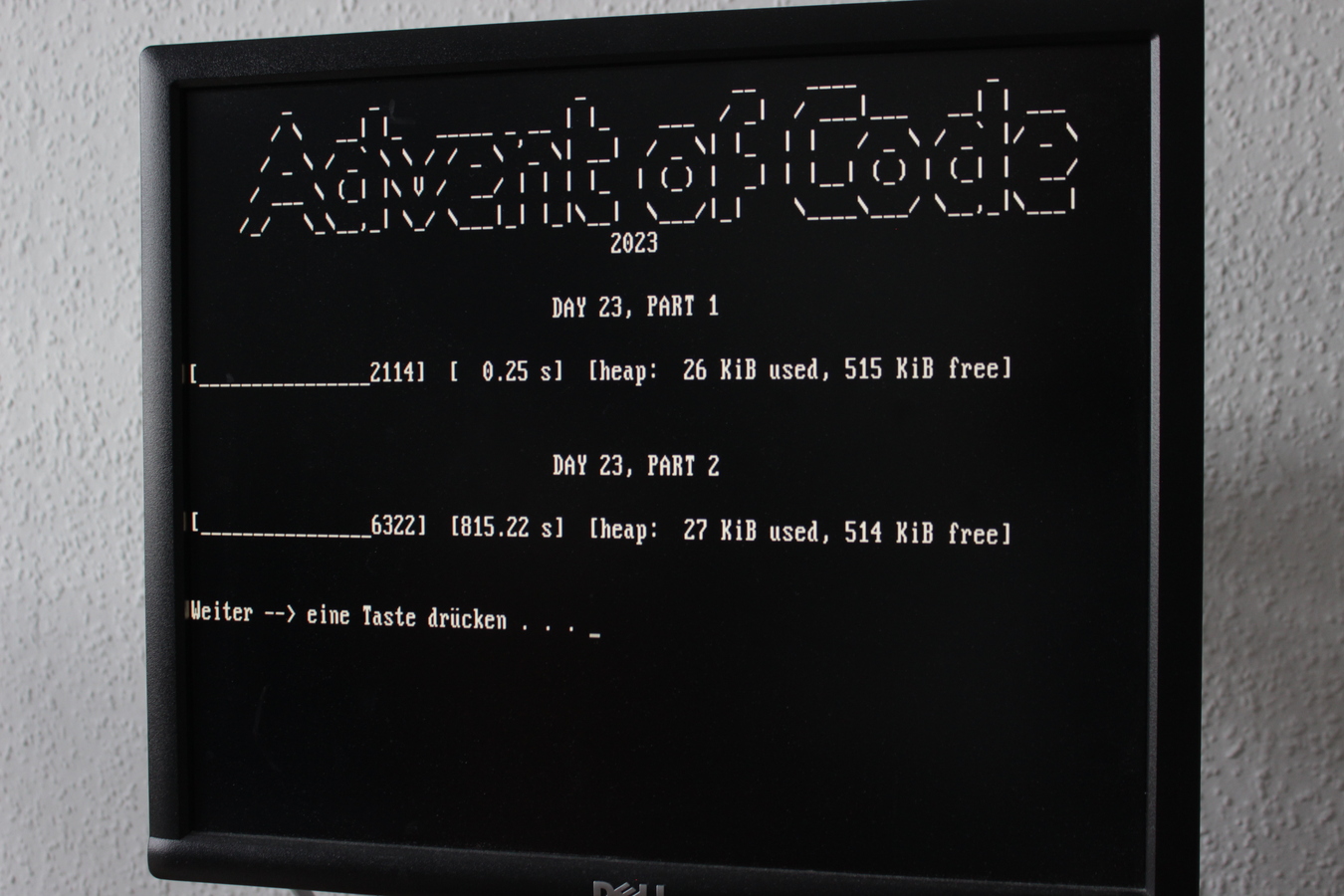
Results
My DOS-ified list of stars this year looks like this (D = runs on DOS,
* no DOS but still got a star – day 25 never has a second part):
1111111111222222
1234567890123456789012345
DDDDDDDDDDDDDDDD*DDDDDDD* Part 1
DDDDDDDDDDDDDDDD*DDDDDD* Part 2
So, out of the 49 puzzles, all but 4 run on DOS. Not too bad!
- Day 17: A path finding problem and I did not have enough memory. Not even Jukka Jylänki on his C64 managed to solve the puzzle without memory extension.
- Part 2 of day 24: This was a bit tricky, because I solved this using Python and Z3. I see no way of porting this to DOS. (Here are some ideas on how to solve it without something like Z3.)
- Day 25: I originally solved this by plotting the graph in
Graphviz’s
neato, which almost immediately revealed the solution. Funny enough, this got me to rank 116, so I almost made it to the global leaderboard after all. Oh, well. Afterwards, I implemented Karger’s algorithm in C – but it’s very inefficient and slow, even on Linux, and runs out of memory on DOS. (I’m lacking some important data structures in my little library. This slows down other days as well.)
Maybe trying to port these to DOS could be a challenge for the next few months, but for now, I’m taking a break. :-)
In this video, I’m copying the compiled code via FTP from my workstation and then I’m running those puzzle solutions that are fast enough to show in a video – since I find it interesting, the video also includes the boot process of the machine:
The others take too long for a video:
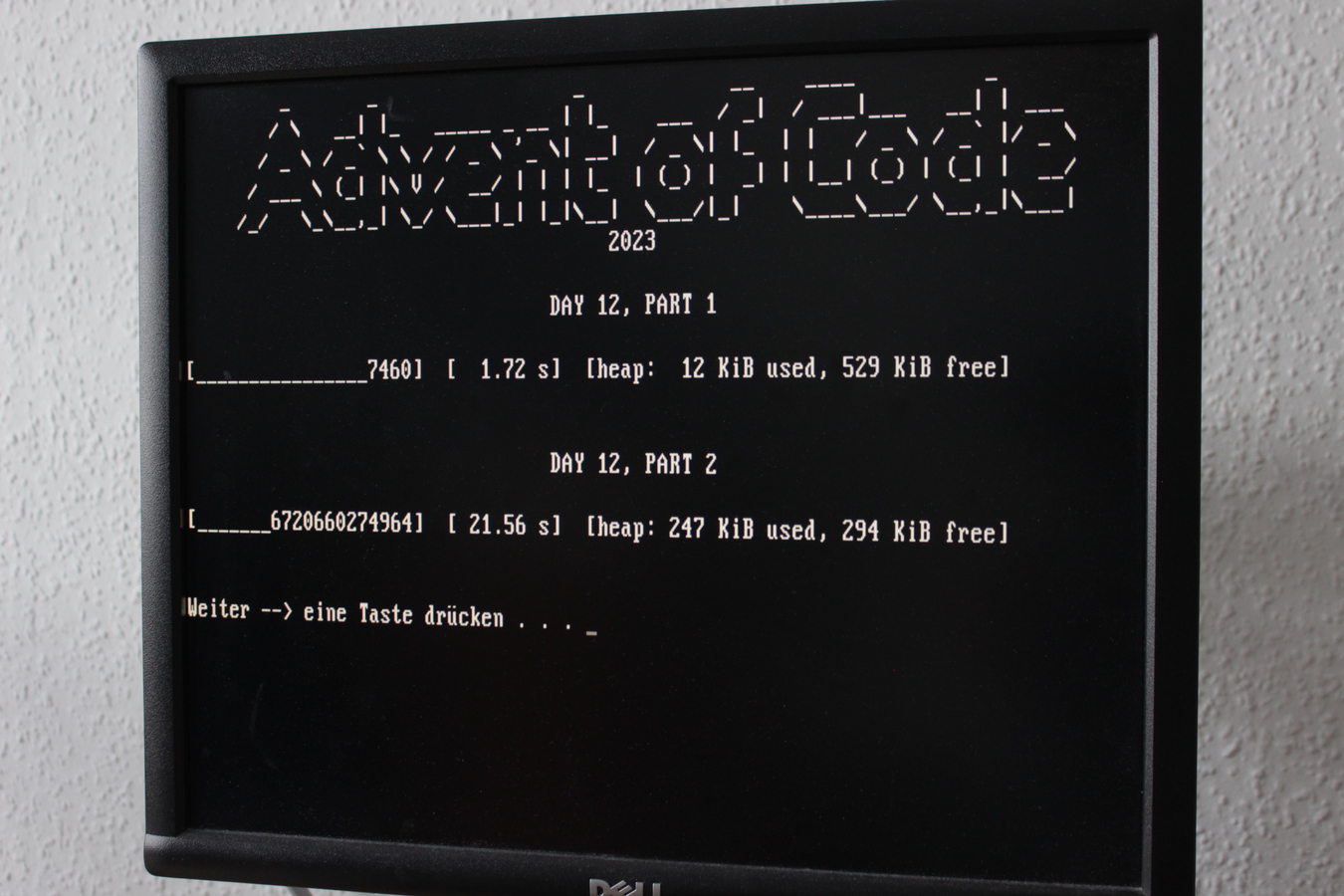
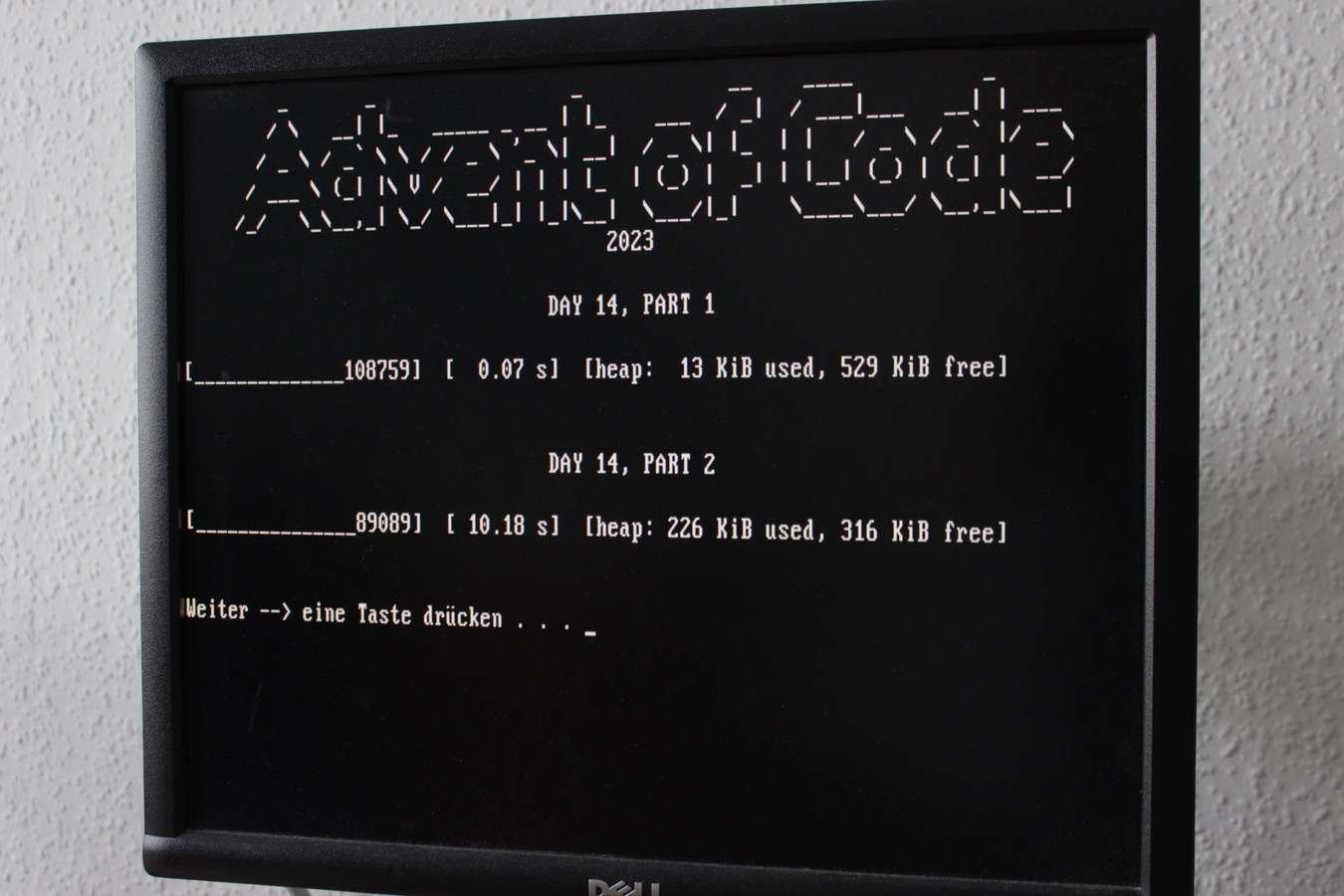
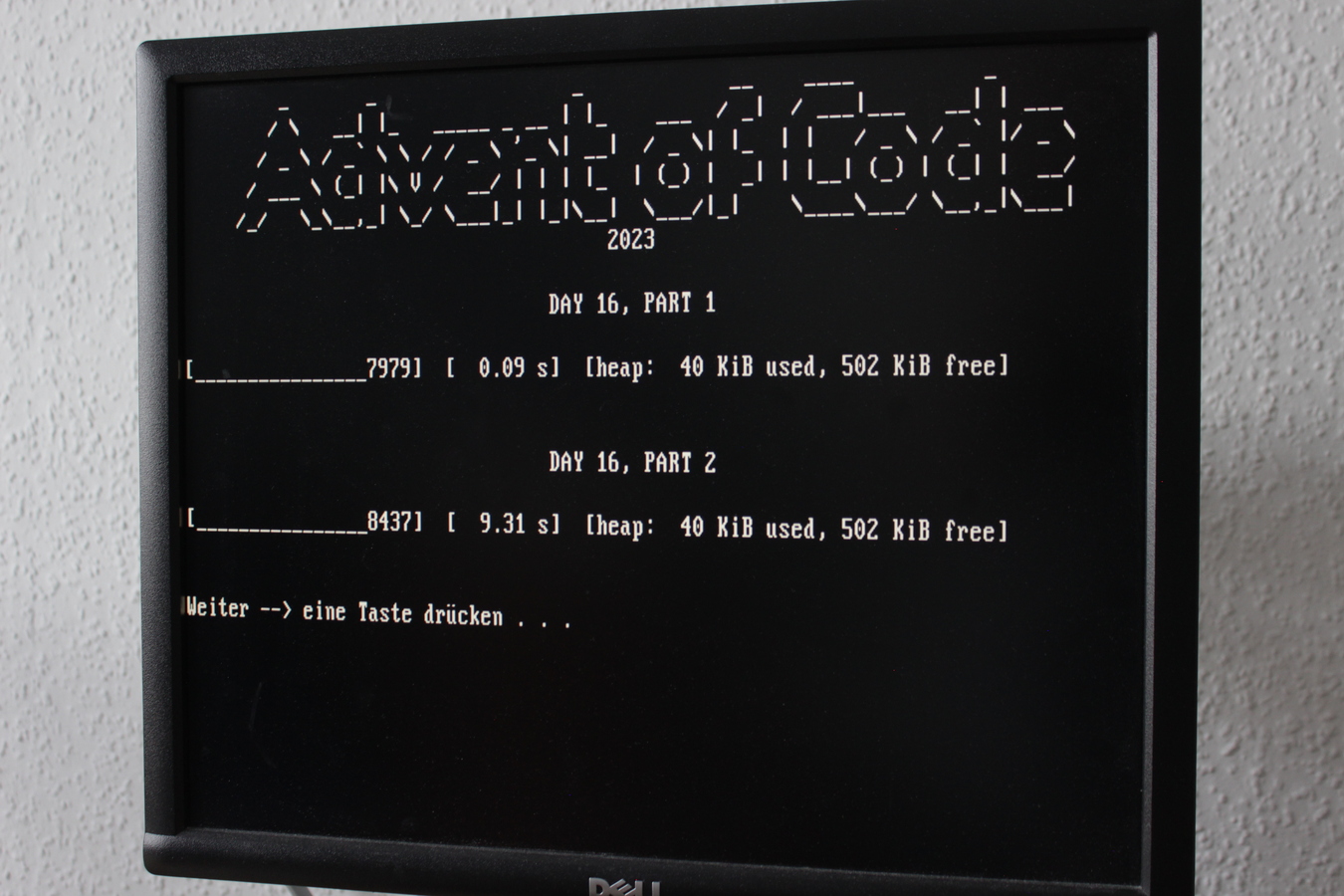
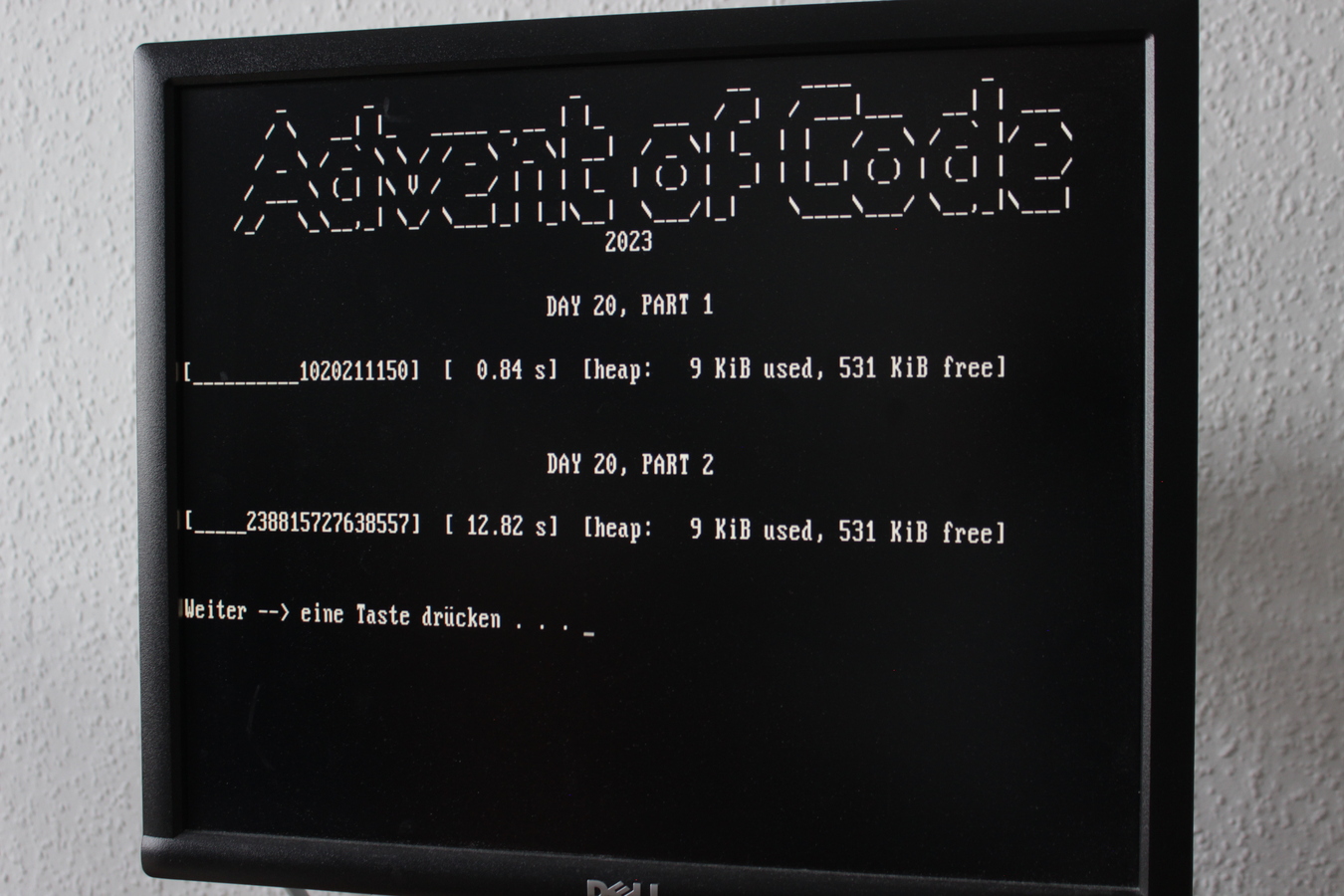
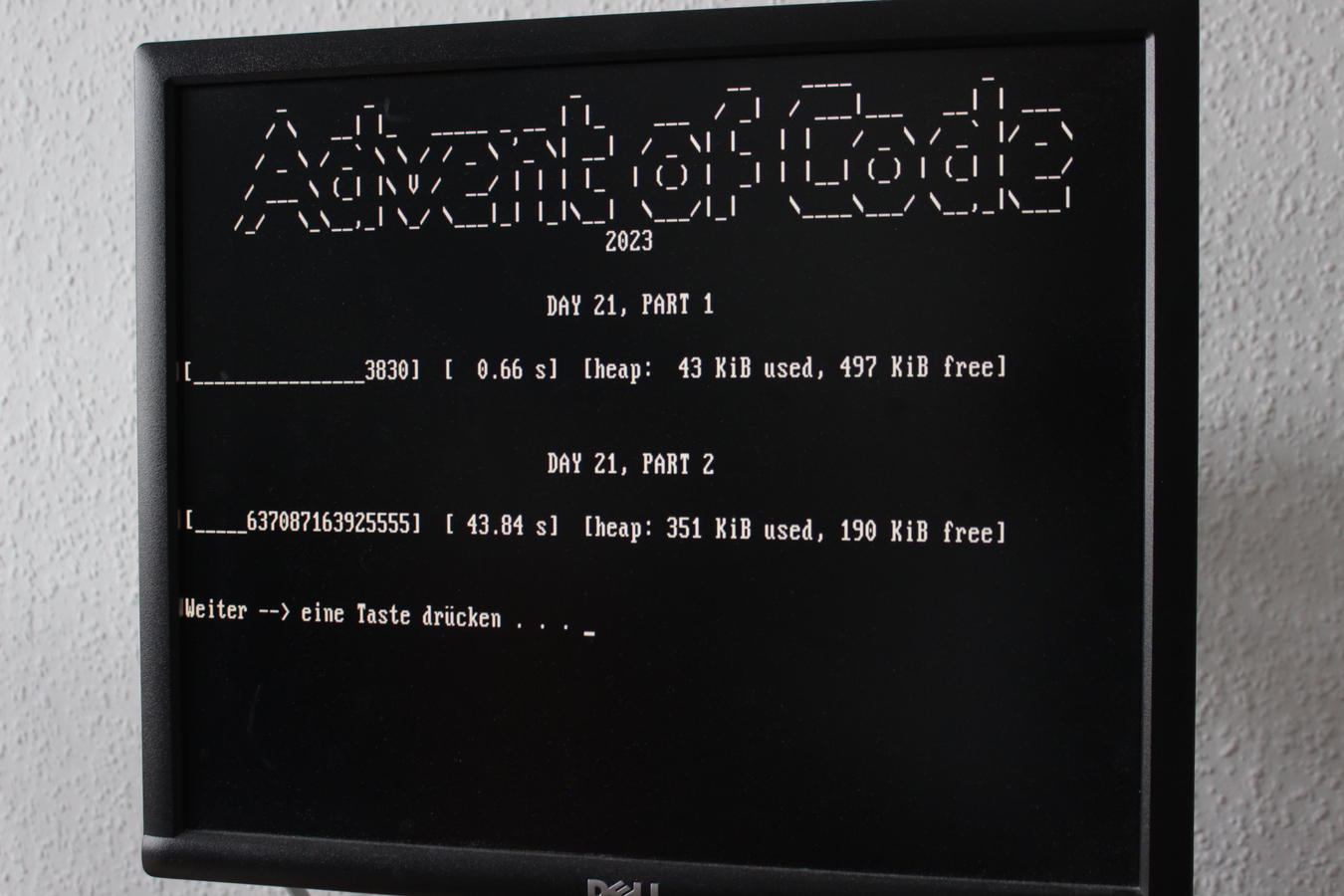
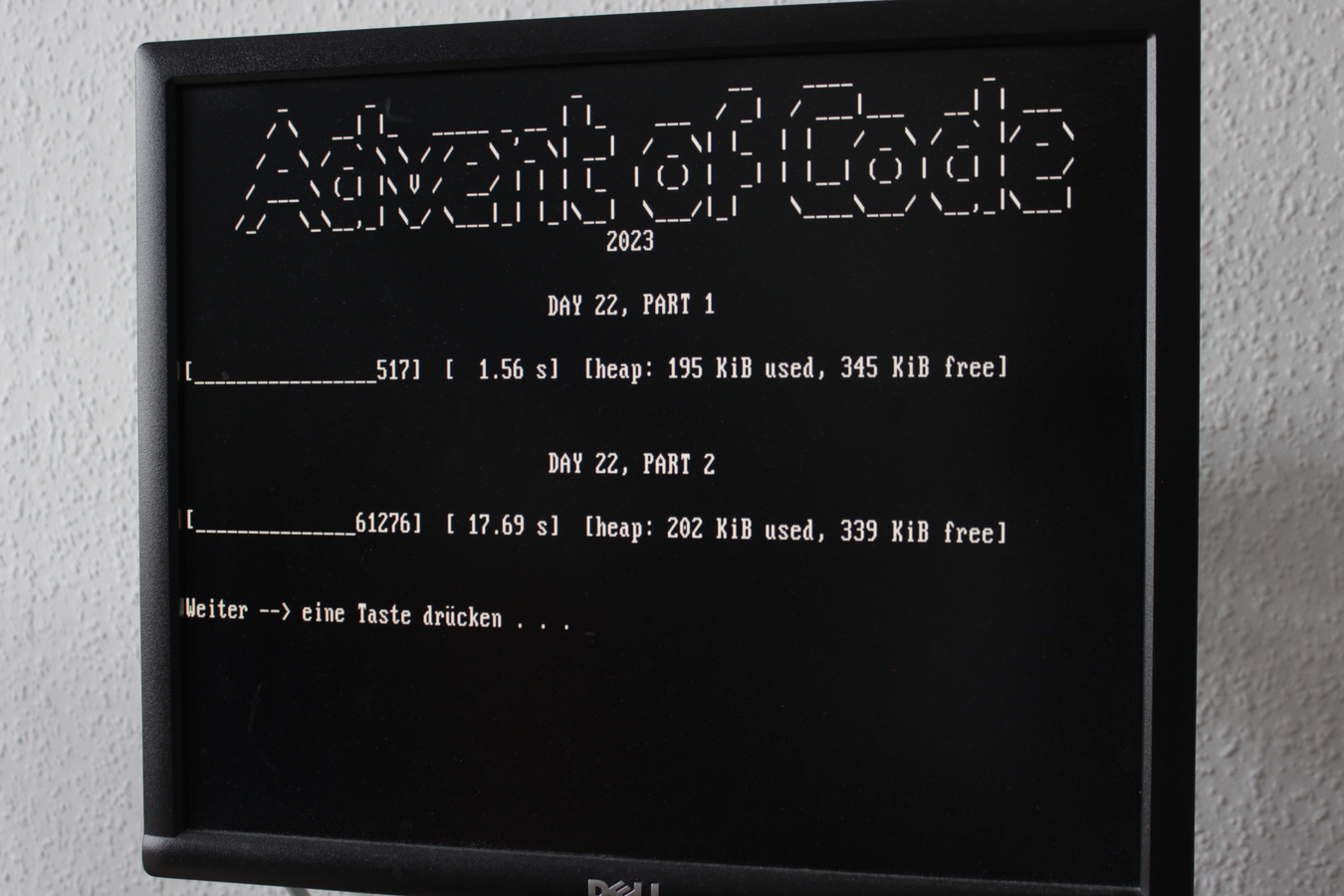
For comparison, this text file shows the runtimes on my current workstation, an i7-3770 from 2013.
I made a couple of visualizations as well:
-
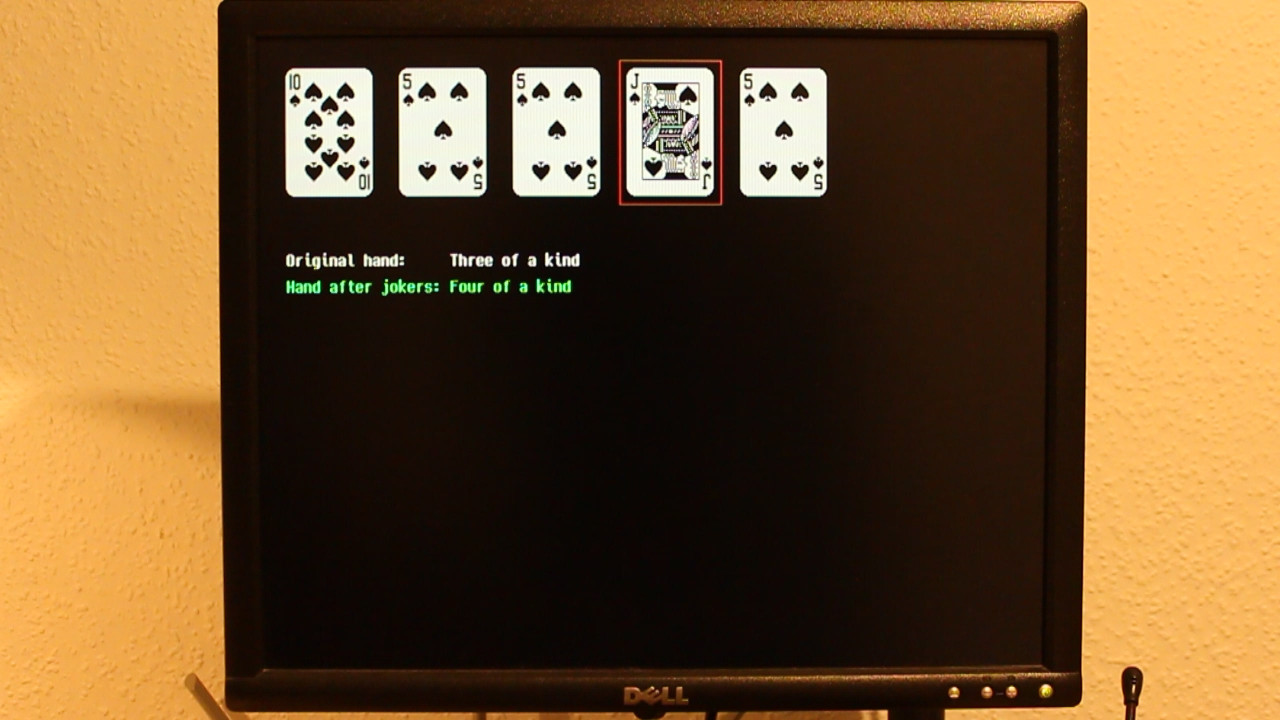
Day 7 (dummy data): Just to get started with graphics. The card images are from TkSol, which I play all the time. :-)

-
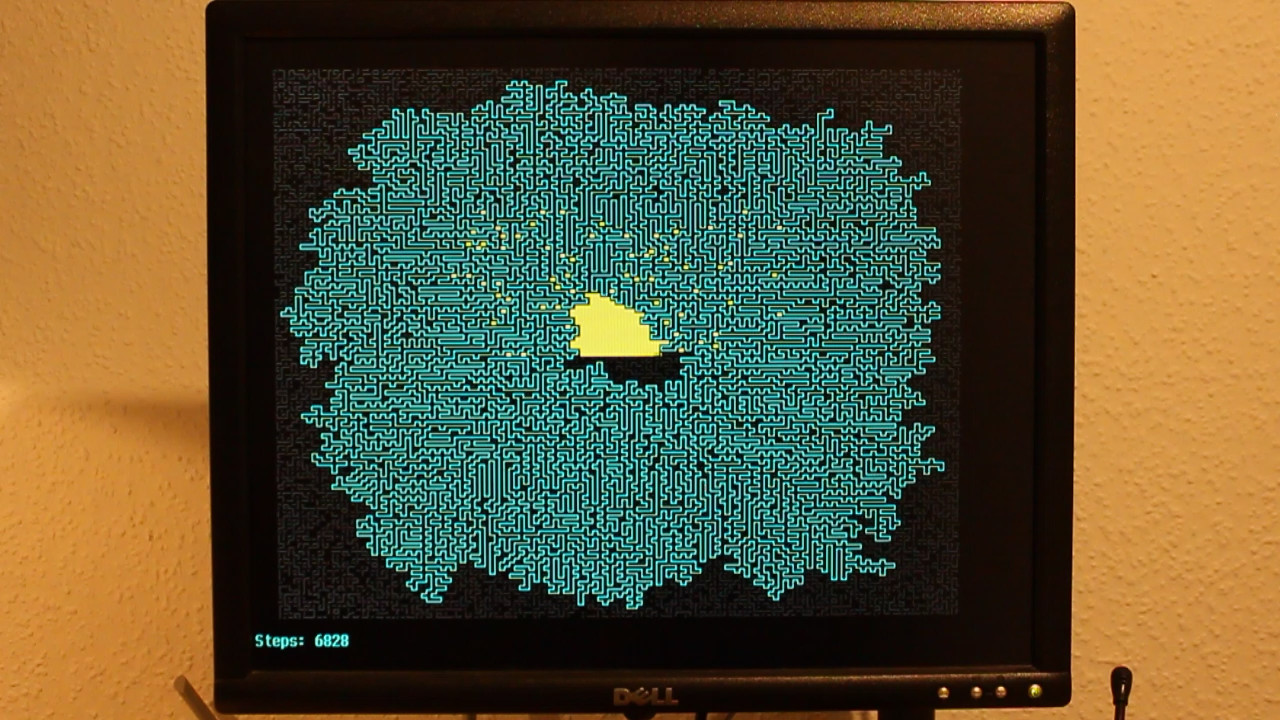
Day 10 (dummy data): Probably my favorite.

-
-

-
-
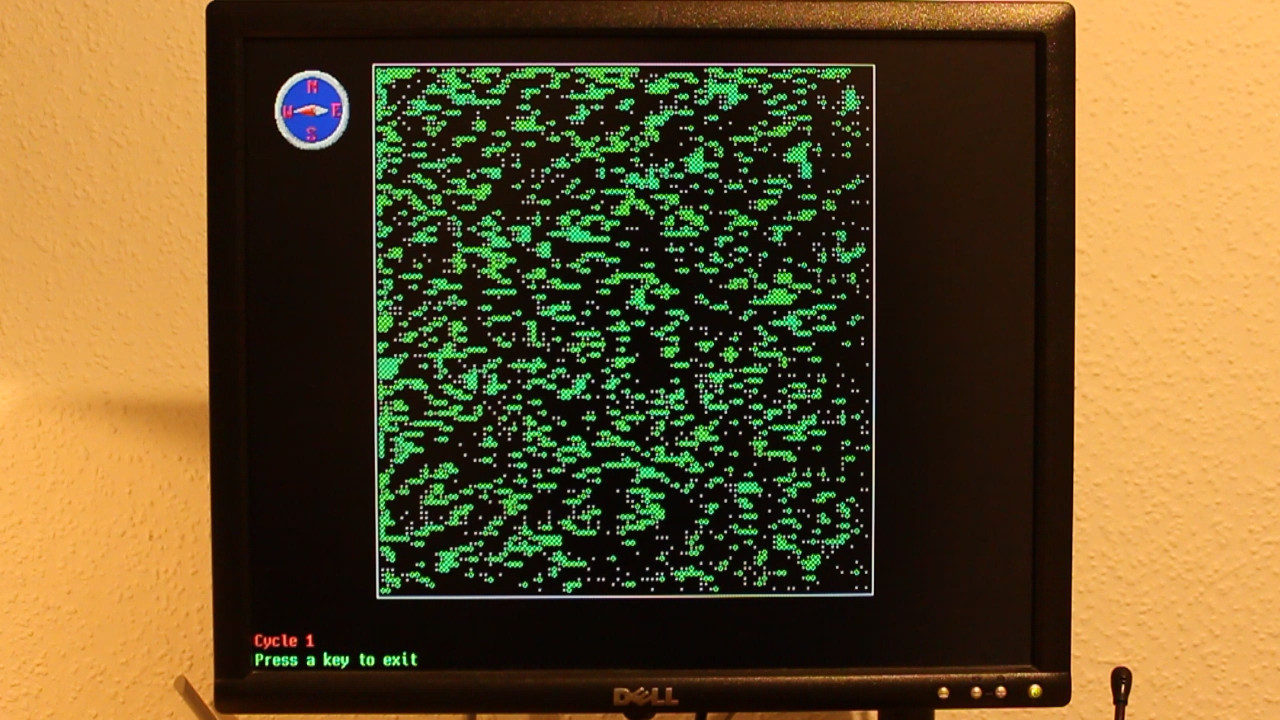
Day 14 (alternate version): An earlier version of the visualization, which shows the actual faster algorithm of the program. It’s not as visually pleasing, though, and it uses an earlier version of the VGA library (more on that later).

-

-
-
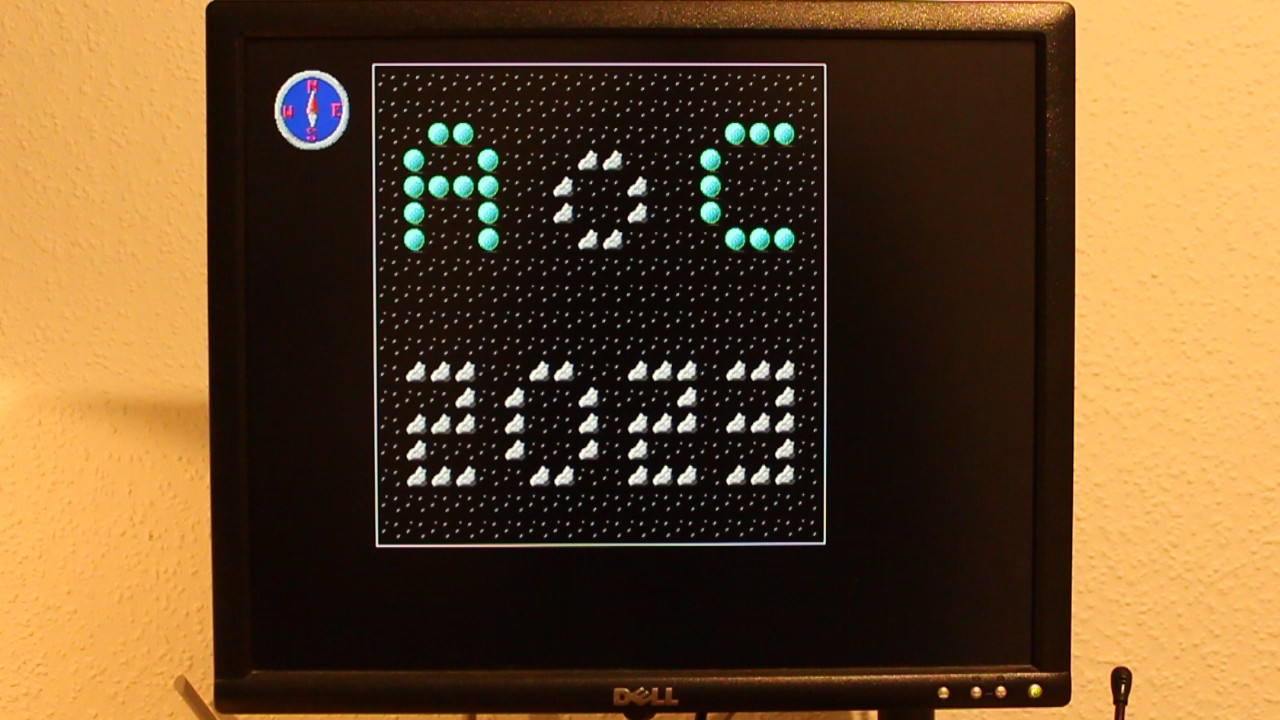
Day 21 (dummy data): Strobe warning. The flickering is not a graphical artifact, it’s because it shows the alternating patterns that are a major part of this puzzle.



(I’m not too happy with the image quality of these photos and videos. Filming a TFT monitor isn’t that easy.)
I posted some more impressions in this thread on Mastodon, but who knows for how long that will be available – it’s not my server, I don’t control that data.
The build VM
I use overqemu for pretty much everything when it comes to virtualization and that includes my DOS VM. It allows me to have a base image that is always clean, because running VMs always get an overlay image. If I want to discard the changes, I can simply remove that overlay – if I want to keep them, I can commit them. I can do whatever I want in the VM without risk.
In its AUTOEXEC.BAT, my VM has a line that checks for the existence
of D:\AUTOEXE2.BAT. If it’s there, it runs it. The D: drive can be
an additional QEMU image attached to the VM. It gets populated by a
copy script in my AoC repo: This script copies all the
source code files and other resources to the image, and also creates a
couple of batch files to build all programs. Finally, it creates the
aforementioned D:\AUTOEXE2.BAT and fills it with a call to the build
script. So, when I start this VM, it automatically builds everything.
I think that’s pretty neat and there are virtually no manual steps
involved.
As a compiler and an occasional IDE, I used Turbo C++ 3.0. Despite the name, all my programs are C. (It doesn’t run very great in the VM, though. I get phantom key presses and sometimes the mouse runs amok.)
What I learned
#0: “Oh, it works!”
I have very little experience when it comes to C on DOS. Back in the day, we only used various versions of BASIC – and I was very young anyway. My first experiments with C were at the end of the 1990ies (I think) and that was already on Linux. So, for this year’s AoC, almost everything I did was “a first”.
My approach to writing the code was to just write it as I would on Linux. The next step was to try to build it in DOS and see if / how it broke.
Especially in the first few days, I was stunned by how often the code
would just work. Sometimes I had to change int to long int, but
that was it. Wow. And not only did it work at all, it was fast on the
museum PC as well. This blew my mind.
#1: Memory and Segmentation
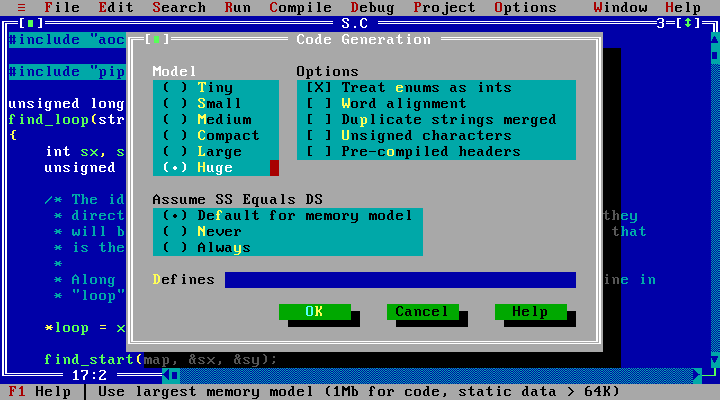
At the beginning, I ignored this topic altogether. I set the memory model to “huge” and went on to solving the puzzles.
The short story is: You get roughly 550-600 KiB of usable heap memory allocated from conventional memory and (without doing anything fancy) the individual objects allocated on the heap can be at most 64 KiB in size.
The more annoying story is that we have to deal with segmentation. On today’s x86_64 CPUs, the address space is just linear and pointers are just single numbers pointing to some byte in that space. Easy. MS-DOS runs in real mode, though, and that complicates things: Memory is addressed by two numbers, a segment selector and an offset inside that segment.
At some point, I wanted to have a little program that displayed images
in 640 x 480 with 16 colors. That is already about 300 kB of data if you
allocate a byte for each pixel. Just calling calloc() here does not
work – it can only allocate up to 64 KiB for a single object. Of course,
I could have found ways to avoid storing the entire image in memory, but
for educational purposes I wanted to get it to work.
This is going to be tricky, because such a large block of data must span several segments: The effective linear memory address is built by combining a segment selector (16 bit) and an offset (16 bit). Since the offset is only 16 bit, you can only cram 64 KiB of data into one segment.
Things get more confusing once you realize that the address line only has 20 bits – but we have two 16 bit values, wouldn’t that give us 32 bits? Nope, these two values are combined as follows:
linear_address = (segment << 4) + offset
In other words, there is no unique mapping back from a linear address to a segment / offset pair. For better or worse, applications decide how large segments should be. And this is entirely “virtual”, the CPU doesn’t care about it (if I understood correctly). One application might use 16 segments of size 64 KiB, another might use 128 segments of size 8 KiB, and the next one mixes all kinds of sizes. At the end of the day, all of them can address 1 MiB.
On the level of C, segmentation is a bit obscured. First, you still just have one pointer to address memory – you usually don’t get to see “segment” / “offset” directly. So if there is a segment selector somewhere, it must be encoded in that single variable.
If you leave everything on default (including the memory model), then
pointers are just 16 bit numbers and they all mean the current segment.
That won’t get you very far. But a far pointer gets you far. :-)
That’s a 32 bit number and it carries both segment and offset.
Problem is, pointer arithmetic doesn’t really work with far pointers.
For that, there are huge pointers and they are what I used in my image
viewer, like so:
#include <alloc.h>
#include <stdlib.h>
#include <stdio.h>
int
main()
{
unsigned long int x, y, width = 640UL, height = 480UL, idx;
char huge *ptr;
ptr = farcalloc(width * height, sizeof (char));
if (ptr == NULL)
{
perror("farcalloc");
return EXIT_FAILURE;
}
idx = 0;
for (y = 0; y < height; y++)
{
for (x = 0; x < width; x++)
{
ptr[idx] = 123;
idx++;
}
}
return 0;
}
A big chunk of data that can be indexed using an unsigned long int
(instead of the smaller size_t). Almost feels like a modern machine.
huge pointers are similar to far points in that they carry a segment
index and an offset, and are actually 32 bit in size. Only huge
pointers allow for indexing as shown above, though. And all of this is
costly: When inspecting the generated assembly code, you’ll see that a
seemingly simple ptr[idx] in C actually calls a function. I guess
this kind of thing isn’t what you would do in a real-world DOS program
that cares about performance.
Another thing to note is that, when setting the memory model to a higher
option, all pointers automatically become far pointers (not huge,
though). Performance suffers from this as well – but I didn’t notice it
for the AoC puzzles.
A bit scary is that information about this topic is hard to get by these days. Nobody uses this anymore and nobody teaches it anymore. I had to do a lot of experimentation and maybe I got some things wrong. Please correct me if you spot mistakes.
All this is talking about the heap, by the way. The stack is much,
much smaller: There were usually only a few kilobytes available. On day
12, a recursive solution was the cleanest one, but it had a depth of 104
for my input. At first, the program just crashed inexplicably, until I
discovered the compiler’s -N option to detect stack overflows. Once I
knew it really was a stack overflow, I could try to reduce the size of
the individual stack frames. The way to go here was to move some
variables to global ones, so they don’t have to be replicated all the
time.
#2: I need larger numbers
Some AoC puzzles generate answers that don’t fit in the 32 bits that I
have available as unsigned long int on DOS. Now what? Write my own
“big int” library? Oof, I’d rather not.
I found a workaround for this, but it felt a bit “dirty” at first: I
used long double numbers. They are 80 bits in total on DOS and have a
63 bits mantissa. I’m quite a bit rusty in this area, but I believe this
data type should be able to accurately represent all 63 bit integers.
You cannot perform all operations on these numbers, but given the
structure of most AoC puzzles, it happens to work: There is usually only
one large number and that’s the final result you’re calculating, which
is usually the sum or product of many small numbers.
I then learned that, in Lua, numbers are always double:
The number type represents real (double-precision floating-point) numbers. Lua has no integer type, as it does not need it. There is a widespread misconception about floating-point arithmetic errors and some people fear that even a simple increment can go weird with floating-point numbers. The fact is that, when you use a double to represent an integer, there is no rounding error at all (unless the number is greater than 100,000,000,000,000). Specifically, a Lua number can represent any long integer without rounding problems. Moreover, most modern CPUs do floating-point arithmetic as fast as (or even faster than) integer arithmetic.
Made me feel a bit less dirty. :-) Still, this isn’t the fastest thing to do on an old CPU.
#3: Drawing graphics using BGI
For day 3, I did a simplistic “visualization” using the functions of
CONIO.H. An interesting thing to do, somewhat comparable to ncurses,
but it’s not what we’re here for.
A next step was using the Borland Graphics Interface (BGI). You can switch to VGA mode and render individual pixels. Some days got a visualization using this framework and the aforementioned image viewer used it as well. It might not be super fast, but it’s rather pleasant and easy to work with.
I had to come up with my own simplistic image format. It’s similar to farbfeld:
Bytes | Description
------+-------------------------------------------------
2 | 16 bit BE unsigned integer (width)
2 | 16 bit BE unsigned integer (height)
[1] | 8 bit unsigned integers (color index), row-major
Color index is either 0-15 for VGA colors or 16 for transparency.
It’s annoying to make such image files directly, so I wrote a little
converter from farbfeld to “.dim” (“DOS Image”). I can then create new
images using GIMP, save them as farbfeld, and then have my
build script run the converter. It does nearest-neighbor matching and
looks at the farbfeld alpha channel to detect transparent pixels
(existing content of the framebuffer will be visible – which is just
black in the parrot photo below).
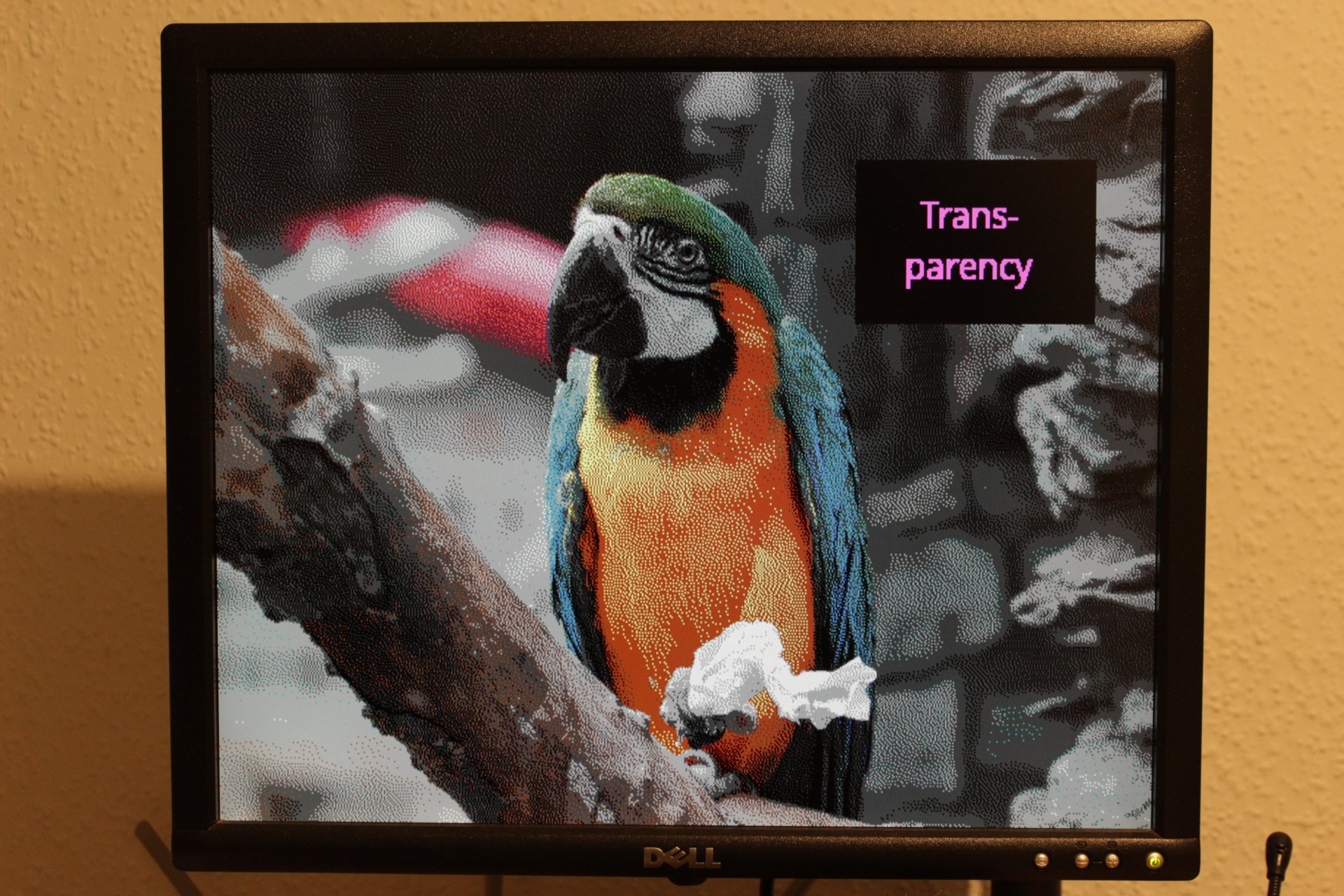
(The dithering in this image was done using GIMP.)
#4: Drawing graphics using a custom VGA interface
(Again, I did my best to find out how this works, but documentation is rather scarce, because everything is so old. If you spot mistakes, please tell me.)
On 2023-12-13, we got a relatively easy puzzle, so I took the opportunity to explore VGA a bit more. Maybe I can use it directly without BGI? Here are a couple of links I collected along the way:
- https://asm.inightmare.org/index.php?tutorial=1&location=11
- https://delorie.com/djgpp/doc/rbinter/ix/10/
- https://en.wikipedia.org/wiki/INT_10H
- https://forum.osdev.org/viewtopic.php?f=13&t=3837
- https://wiki.osdev.org/Drawing_In_a_Linear_Framebuffer
- https://wiki.osdev.org/VGA_Hardware
- https://www.ctyme.com/intr/int-10.htm
- http://www.wagemakers.be/english/doc/vga
“Mode 13h” (320 x 200 with 256 colors) is great: It fits exactly into one segment and you can address each pixel directly. It’s fast, too.
But it’s really small. I wanted to give “mode 12h” (640 x 480 with 16 colors) a try, as that is what I used with BGI before.
And that is where the headache starts.
As we’ve seen above, 640 x 480 pixels with one byte per pixel is too much for one segment. We just use 16 colors anyway, that’s 4 bit, so we could put two pixels into one byte – but that still doesn’t fit into one segment: (640 / 2) x 480 = 153'600.
VGA “solves” this by working with color planes. You tell it: “I will now write to the blue color plane.” And then all you need per pixel is one bit, i.e. “blue color on / off for pixel x = 100, y = 53”. That means we can cram eight pixels into one byte: (640 / 8) x 480 = 38'400. Fits neatly into one segment – and it’s super awkward in this day and age.
To elaborate some more, you have a buffer that is 38'400 bytes long, and in this buffer, the following pixels correspond to the following bits (bit numbers start at 0, i.e. “bit 7” is the left-most bit, 0x80):
- Pixel (0, 0): Byte 0, bit 7
- Pixel (1, 0): Byte 0, bit 6
- Pixel (2, 0): Byte 0, bit 5
- Pixel (3, 0): Byte 0, bit 4
- Pixel (18, 0): Byte 2, bit 5
- Pixel (0, 1): Byte 80, bit 7
- Pixel (1, 1): Byte 80, bit 6
- Pixel (0, 2): Byte 160, bit 7
- Pixel (1, 2): Byte 160, bit 6
- Pixel (123, 456): Byte 36495, bit 4
The program imgtools/vgaidx.c in the repo can be used to explore these
indices a bit more.
Alright, so you now have four planes (0 = blue, 1 = green, 2 = red, 3 = brightness) and a 38'000 bytes long buffer for each of those. How exactly do you get these on the screen?
First, you must switch to the desired VGA mode. As I said, I used “mode 12h” (to switch back, go to mode 3h):
mov ax, 0x12
int 0x10
In C, you can use this instead:
union REGS r;
r.x.ax = 0x0012;
int86(0x10, &r, &r);
Once switched, you activate the blue plane and dump all your pixels into memory beginning at 0xA000:
unsigned char far *v;
v = MK_FP(0xA000, 0);
outport(0x03C4, 0x0102);
_fmemcpy(v, buf_blue, (640 / 8) * 480);
The MK_FP macro creates a far pointer to the desired segment / offset.
outport(0x03C4, 0x0102) is writing the value 0x01 to the I/O
port 0x03C4 at index 0x02. That is the map mask
register. To select the four planes, use these values (you always
dump to the memory address 0xA000):
- Plane 0, 0x0102, blue.
- Plane 1, 0x0202, green.
- Plane 2, 0x0402, red.
- Plane 3, 0x0802, brightness.
Yes, this is dumping all pixels in one go – not individual pixels.
Addressing single pixels is really cumbersome and really slow. I
suspect that BGI does this and that’s probably why it’s so slow. So
instead, I really did malloc() four buffers of normal memory and then
my vga_putpixel() function only sets the appropriate bits in those
“local” buffers. After all drawing operations for a frame are finished,
I call vga_emit() which does nothing but the four outport() calls
followed by a _fmemcpy() each. (As a side effect, this is basically
double buffering which results in a bit less flickering.)
You can see the whole thing in include/dos_vga.h in the repo.
Obviously, you now need an additional ~150 kB of memory all the time. My AoC visualizations can afford that.
So, how fast is this then? It depends. DOSBox, QEMU and my real hardware
react very differently. For example, no matter what I did, QEMU is
capped at about 19 calls of vga_emit() per second. DOSBox could ramp
up to 1000 of those, my real hardware to about 80. Interestingly, the
number of vga_putpixel() calls have very different effects: In QEMU,
touching each pixel (i.e., drawing a full new frame) still gives me ~14
fps, whereas DOSBox now drops down to ~4 fps – and my real hardware goes
down to ~2.8 fps.
Now, making an actual game this way would never work. Am I doing something fundamentally wrong or is this just how it is? Maybe mode 12h just isn’t any faster? All this twiddling with bits is just a lot of overhead.
It took me a second to realize that many old games indeed do run in 320 x 200 with 256 colors by default, among them Descent, Duke Nukem 3D, and even Carmageddon. I remembered them very differently, not pixelated at all. :-) I even played Carmageddon recently. It’s really astounding that you can cram a full 3D world into so few pixels.
Then eventually the setup program of the somewhat lesser known game TekWar caught my eye:
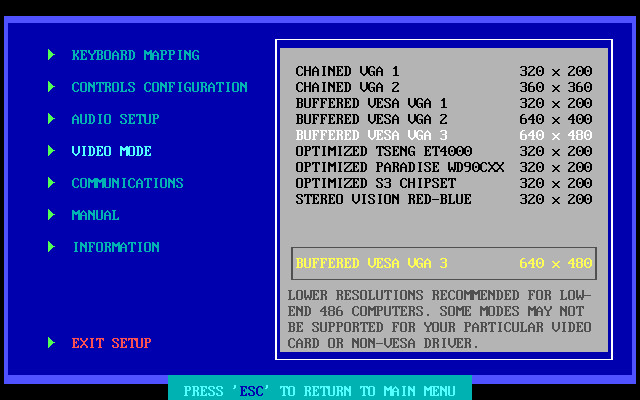
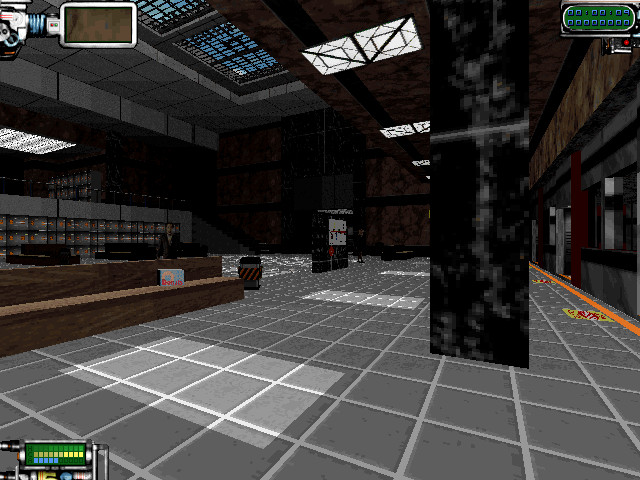
The VESA BIOS Extensions are not what I’m using. Maybe this is the key to better performance in higher resolutions, but I haven’t explored this during AoC. (I’ve since remembered that Duke 3D supports VESA modes as well.)
In hindsight, I probably shouldn’t have insisted on using mode 12h. Mode 13h would have given me more freedom doing the actual visualizations (because it’s faster, so I can do more things) and, frankly, I would have gotten a more “retro” look, because the output is more pixelated after all.
Either way, my custom code sure is much faster than BGI and often fast enough for those little AoC visualizations. I subsequently ported all my programs to this new backend instead of BGI.
One neat side effect is that I can now easily use my fiamf3 font. Maybe this would have worked with BGI as well, I didn’t check. But now without BGI, I have to implement text rendering myself anyway and that also means I have to provide my own font files.
#5: How about using more memory?
Games used to come in boxes (believe it or not!) and the “system requirements” were printed on the box. Here’s Grand Theft Auto from 1997:

It says it wants DOS 6.0 and 16 MB of RAM. I either never really thought
about what that means or I forgot. It runs on DOS but it can use 16 MB
of RAM? How? As it turns out, these games do not run in real mode – they
use a DOS extender to run in protected mode. That’s
the famous DOS/4GW banner that shows up on virtually every semi-modern
DOS game. And in protected mode, you can address memory using 32 bit
pointers. Boom.
Do I want to use that for AoC? I decided not to – because how would that be different from just running my code on, say, 32 bit OpenBSD? I decided that “the DOS experience” includes being limited to ~640 KiB.
Are there any other options? Well, there is EMS and XMS.
Of these two, I only gave XMS a shot. Here’s an example. As you
can see, the only thing you can do with it is manually copy data to and
from extended memory by calling some magic functions that are provided
by HIMEM.SYS. So, it’s not like you get a magic
xms_malloc() function or something like that, and then you can use
magic pointers. No, you just get a handle.
(Internally, HIMEM.SYS uses unreal mode.)
My XMS example program runs reasonably fast in my QEMU VM – but super slow on real hardware.
EMS follows a different model, but at the end of the day, it’s the same thing: Both EMS and XMS allow you to move data out of conventional memory and, thus, allow you to use much more than just 640 KiB, but once the data is there, you can’t easily access it anymore. It’s practically gone from your 20 bit address space and you have to do expensive things to get it back. EMS and XMS are “better than nothing”, but far from being easy to use and nothing like using protected mode or long mode.
Day 17 and 25, the only days that posed memory problems, would have been really awkward to implement using EMS or XMS. I didn’t do it and I guess it would have been unusably slow.
#6: Floating-point exceptions do funny things
On modern systems, it is perfectly legal to do this:
#include <stdio.h>
int
main()
{
double a, b, c;
a = 1;
b = 0;
c = a / b;
printf("%lf\n", c);
return 0;
}
It will print inf.
When compiled with Borland’s Turbo C++ 3.0 on DOS, it just freezes.
Or … does something interesting: Switch to another VGA mode.
It appears that division by zero triggers a CPU interrupt and that
happens to be the same one that we used to switch modes: 0x10.
(More on this clash.) If we arrange for a valid value in
the AX register, then we will end up in exactly that mode (instead of
just a freeze):
a = 1;
b = 0;
asm { mov ax, 0x0013 }
c = a / b;
That’s cute, but not particularly useful. What I would like is that 1.0
/ 0.0 produces inf and -1.0 / 0.0 produces -inf, as those are
sometimes useful results (think about doing just a comparison, e.g. x /
y > n – using infinities here happens to work out). And most of all,
the program shouldn’t just freeze. Debugging such freezes cost me quite
some time on day 24.
At first, I tried to provide my own ISR, but that’s not really the way to go.
As it turns out, you can instruct the floating-point unit not to
generate interrupts / exceptions when it tries to divide by zero. The
FPU Control Word determines what will happen. We want to set
bit number 2, so that no zero divide exceptions shall be generated and,
instead, the FPU creates inf values directly. This can be done either
using some inline assembly:
unsigned int fpucw;
asm { fstcw fpucw }
printf("%u %u\n", fpucw, fpucw & 4);
fpucw |= 4;
asm { fldcw fpucw }
Or using a C function:
_control87(4, 4);
And now it prints +INF and -INF:

I didn’t actually need this behaviour in the end (I managed to avoid dividing by zero in the first place), but it’s good to know.
Conclusion
What a month. It was quite exhausting at times – part 2 of day 21 comes to mind. I should have looked for help or clues earlier, like I promised myself. :-)
My favorite puzzle was day 20, I think. Analyzing the graph and figuring out what it does and why, that was fun. The experience was a bit similar to day 24 of 2021 (my favorite one of all the puzzles I did so far), which I did entirely on paper back then.
In the end, I’m pretty happy that I got so many puzzle solutions to run on DOS. :-) And I learned a ton. I’d love to make a little game in VGA mode 13h now. Maybe I’ll do just that.
– edit: There you go. DOS games.